> ## Documentation Index
> Fetch the complete documentation index at: https://base.bangwu.me/llms.txt
> Use this file to discover all available pages before exploring further.
# Information analysis
> Course notes on information analysis covering patent law, research variables, sampling, Cronbach alpha reliability, regression models, and factor analysis.
写在前面
信息分析复习由知识点和SPSS相结合,然后按照课件进行总结。本文只是自己总结,可能去看课件会更好一点
复习重点:
1. 专利法的内容
2. 研究设计中:变量,如调节变量、中介变量
3. 调研设计:抽样、量表:什么是量表,量表的信度效度用什么来做检验
4. 回归分析:相关分析,一元线性回归,多元线性回归,logistic回归
5. 因子分析
6. 聚类分析
7. 比较分析:t检验
8. 给出不同的问题和场景,设计信息分析的设计思路、数据源、分析方法、分析过程、应用等(包括评价型信息分析、预测型信息分析等)
| 题型 | 数量 | 分值 | 总分 |
| -------- | -- | -------- | -- |
| 单选题 | 10 | 1 | 10 |
| 多选题 | 8 | 2 | 16 |
| 辨析题 | 6 | 2 | 12 |
| 计算与数据分析题 | 3 | 15, 7, 6 | 28 |
| 论述题 | 3 | 12,12,10 | 34 |
# 一、专利法的内容
> `专利`(patent),是“专利权”的简称。指一项发明创造,即发明、使用新型或外观设计向国务院专利行政部门提出专利申请,经依法审查合格后,向专利申请人授予在规定的时间内对该项发明创造享有的专有权。
>
> 专利的类型:**发明专利、实用新型专利【有的国家没有此项】、外观设计专利**
专利一词的三层含义:
* 受专利法保护的发明创造——(技术角度理解)
* 专利权——(法律角度理解)
* 专利说明书等专利文献——(文献角度理解,查专利查的就是专利文献)
> 获得专利的实质条件:**新颖性**、**创造性**、**实用性**
>
> 专利的`特点`:无形、专有、地域【不同国家,法律的地域性限制】、时间【有有效期】
| | 发明 | 实用新型 |
| -- | ----------------------------- | ---------------------- |
| 对象 | 针对产品和方法 | 只针对产品,而且必须是有固定形态和结构的产品 |
| 要求 | 有突出的实质性特点和显著进步 | 实质性特点和进步 (略低) |
| 时间 | 20年 | 10年 |
| 程序 | 有实质审查 | 只有初步审查,不经实审即可授权 |
| 费用 | 申请费950元审查费2500元,年费900-8000元/年 | 申请费500元,年费600-2000元/年 |
> 国际专利分类法(International Patent Classification)简称IPC【每五年更新一次】
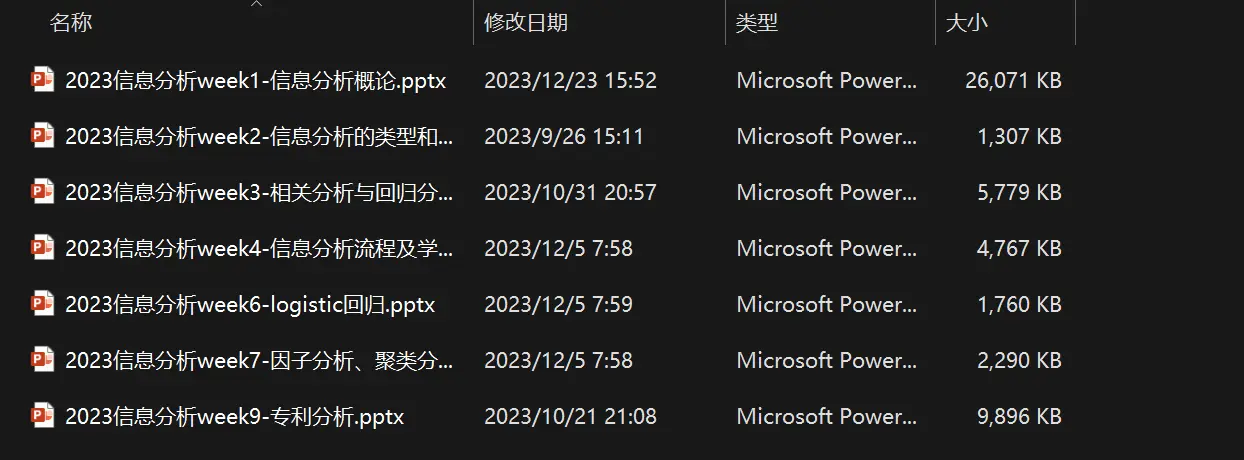
**专利信息产生的流程**:
专利信息的分析对于企业的`技术情况`、`经营环境分析`、`侵权分析`等等【因为专利中蕴含着`法律信息`、`经济/商业信息`、`技术信息`】
# 二、研究设计中:变量,如调节变量、中介变量
> `调节变量`:一个变量X1影响了另一个变量X2对Y的影响
当检验中发现一个显著的调节作用存在时,下一个重要的步骤就是**分析它的作用模式**。这时,如果调节变量和自变量都是定类变量,可以在不同的组中分别计算因变量的均值,然后用得到的值来做图,直观地表示出调节作用的模式。第二种方法是在按调节变量所分的不同组中,检验自变量对结果变量回归的斜率。
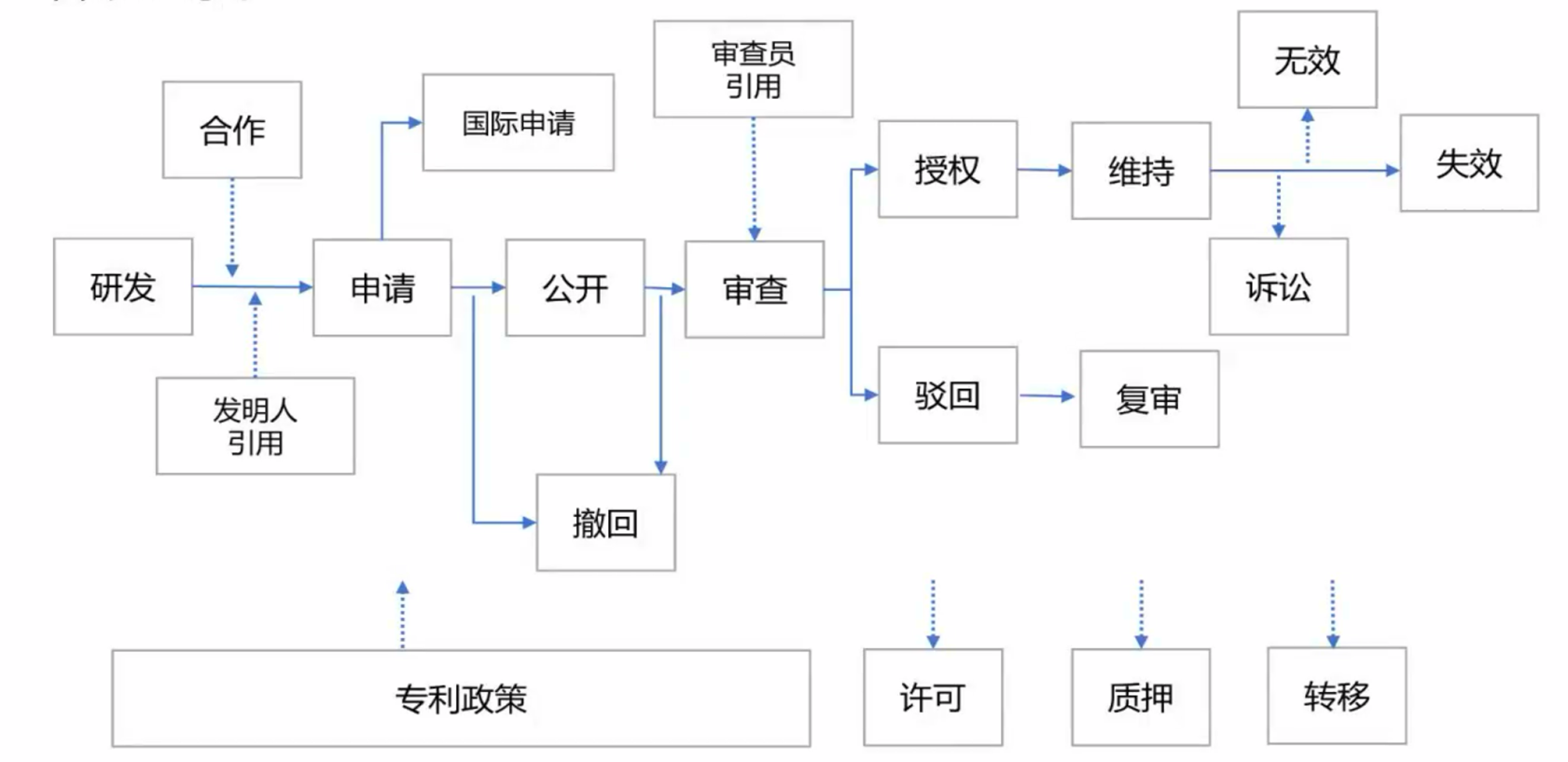
> `中介变量`:简单地说,凡是 *X* 影响 *Y*,并且 *X* 是通过一个中间的变量 *M* 对 *Y* 产生影响的,*M* 就是中介变量。
**部分中介作用**:
**完全中介作用**:

# 三、调研设计:抽样、量表
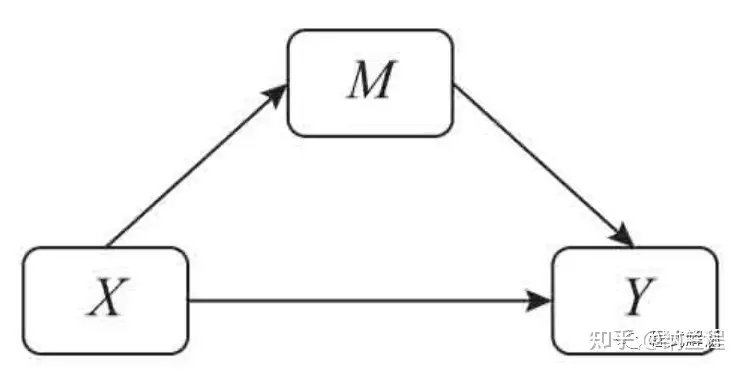
> `抽样`:是指按照一定程序从研究对象总体中抽取部分样本,收集这部分样本的资料,运用数理的原理和方法,对总体特征进行推断的一种非全面的调查。
> 什么是量表
量表是由测量某一抽象概念的所有测量指标和备选答案构成的调查表。
量表是测量调查对象的主观特性的度量标准,是由一组问题和陈述构成,并根据受访者可能的反应方向和强度,被相应地赋予一定的分值。
> 量表的信度效度用什么来做检验
`信度`(reliability)指测量结果的一致性或稳定性。用同一测量工具对同一样本测量两次,求两组数据的相关系数,并以此作为信度的描述的指标,称为信度系数。信息系数r=1是理想状态,表示不存在随机误差。r=0是另一个极端状态,表示所有测量之无任何程度的稳定性。
**对信度的测度一般用内部一致性来测。**【内部一致性信度常用`同质性信度`来测量】
`同质性信度`:指测验内部的各题目在多大程度上考察了同一内容。同质性信度低时,即使各个测试题看起来似乎是测量同一特质,但测验实际上是异质的,即测验测量了不止一种特质。
`效度`(validity)指测量工具对调查对象属性的差异进行测量时的准确程度。即测量工具能否真实、客观、准确地反映属性的差异性。效度高不仅意味着排除随机误差的能力强,同时也意味着排除系统误差的能力强。从不同的角度看待测量的准确性,就有3种类型的效度概念。
1. `内容效度`:内容效度(content validity)指测量工具的题目是否符合测量目的与要求,即测量内容的适合性和相符性。对内容效度的判断常用逻辑分析法、专家判断法等。
2. `准则效度`:准则效度(criterion-related validity)指当可以用不同的测量工具对同—组测验对象的同—属性进行测量时,以其中一种测量工具为基淮,而拿其他测量工具与之作比较,如果所测结果与基准工具所测无差异,就称其他测量工具有效。正因为这样,准则效度又称为实证效度(pragmatic validity)。
3. `结构效度`:测量结果体现出来的某种结构与测值之间的对应程度。结构效度分析采用的主要是因子分析(验证性因子分析)。
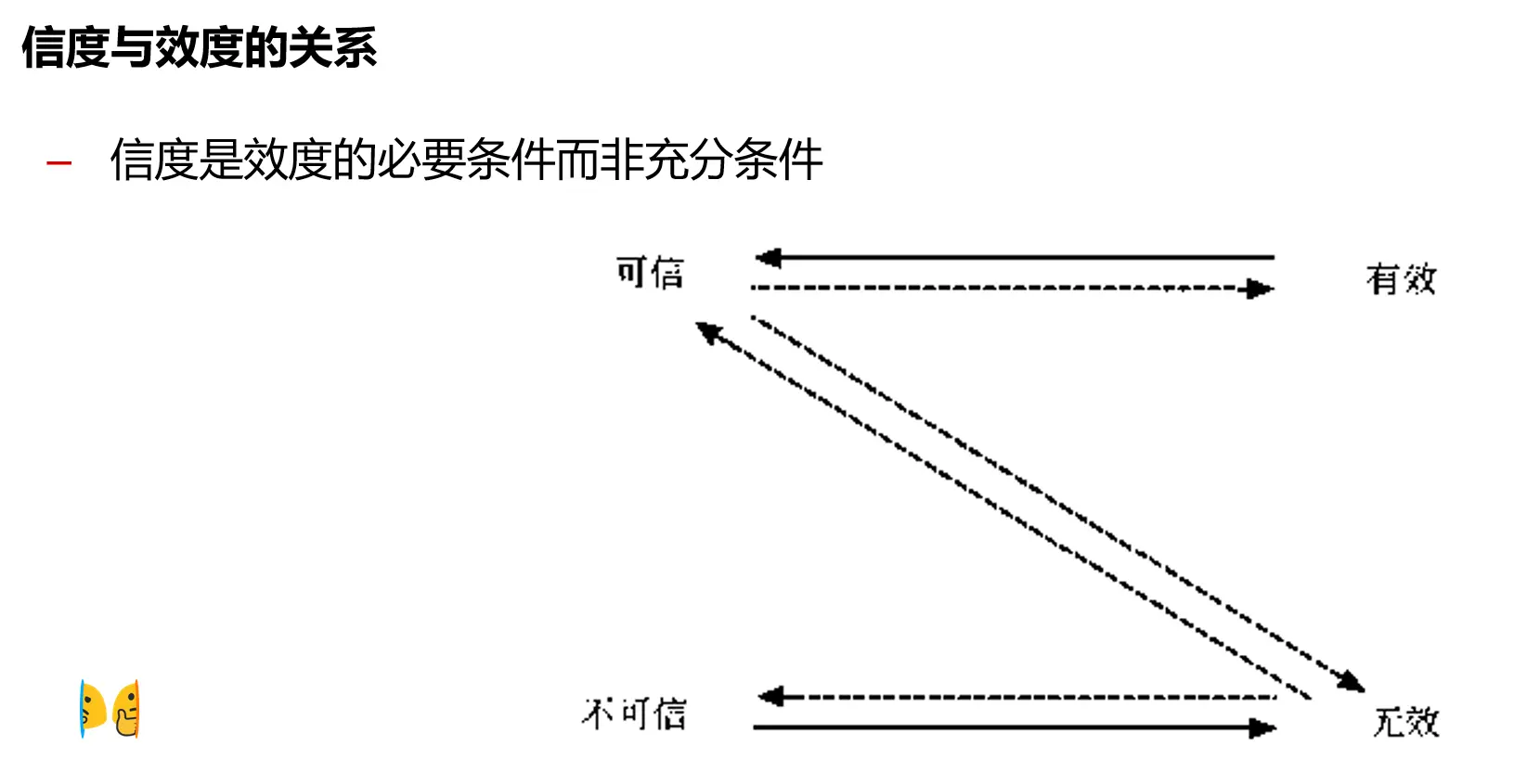
即一个测量工具必须是信度的,才能是有效的,但一个测量工具是信度的,并不一定就是有效的。
# 四、回归分析
**回归分析是通过其他变量来预测某一变量的值。是一种预测分析方法。**
回归分析是主要**解决两个问题**:
1. 确定变量之间是否存在相关,如果相关,分析研究一个或几个变量的变动对另一个变量的影响程度,求出它们的数学表达式;
2. 用自变量的已知值去推测因变量的值或范围,且要估计这种预测达到何种精准度
> 回归分析的基本步骤
1. 确定自变量(解释变量)和因变量(被解释变量)
2. 确定回归模型:从样本数据出发确定变量之间的数学关系式
3. 建立回归方程:对回归方程的各个参数进行估计
4. 对回归方程进行各种统计检验
5. 利用回归方程进行预测
## 相关分析
> `相关关系`的基本概念:立足于实证研究,世间万物之间的关系可以分为三种类型(变量划分)【因果关系、虚无关系、相关关系】
> `相关分析`( correlation)是指变量之间的不确定的依存关系。它和函数关系不同。
> α表示原假设为真时,拒绝原假设的概率
>
> 1-α 为置信度或置信水平,其表明了区间估计的可靠性
为了衡量双变量之间相关关系的强弱程度,所采用的一个基本的指标是简单相关系数r ,也称为`皮尔森相关系数`
相关系数 `|r| <= 1`,r 为负数就是负相关,正数就是正相关,为 0 时不相关
| \| r \| 的数值 | \*\*<\*\*0.3 | **0.3**~0.5 | \*\*>\*\*0.8 | **0.5**~0.8 |
| ------------ | ------------ | ----------- | ------------ | ----------- |
| 相关强度 | 无相关 | 低度相关 | 高度相关 | 显著相关 |
> `偏相关系数`:即在两个以上的多变量的线性相关分析中,当其他变量固定不变时,给定的任何两个变量之间的相关系数
例子:研究身高、体重、肺活量三者的相关关系时,肺活量与体重,肺活量与n回归分析是主要解决两个问题:
–确定变量之间是否存在相关,如果相关,分析研究一个或几个变量的变动对另一个变量的影响程度,求出它们的数学表达式;
–用自变量的已知值去推测因变量的值或范围,且要估计这种预测达到何种精准度身高都存在一定的正相关关系。如果将体重固定下来,对相同体重的人分析肺活量与身高的关系,是否仍然相关?反映的才是真是的相关关系。
**但是相关系数的数值并不能证明所讨论的现象之间是否存在因果关系。**
**若求的r等于或接近于0,只表明现象之间不存在线性相关,而不能反映现象之间是否存在非线性相关。**
> 1. 连续数据,正态分布,线性关系,用pearson相关系数是最恰当。
> 2. 上述任一条件不满足,就用spearman相关系数。
> 3. 两个定序测量数据之间也用spearman相关系数,不能用pearson相关系数。
## 一元线性回归
> 最小二乘法
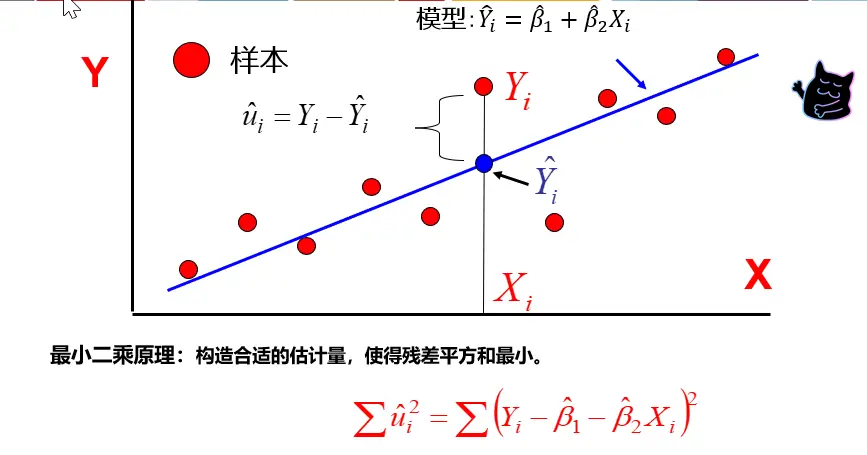
**显著性检验**:
判定系数R的平方【R方在0.8以上,即可认为拟合程度较高】 `t检验` `F检验`
> 一元回归中,F检验与t检验一致,即: F=t方,两种检验可以相互替代
>
> 但在多元回归分析中,它们是不等价的。T检验只是检验回归方程中各个系数的显著性,而F检验则是检验整个回归关系的显著性。
## 多元线性回归
线性回归模型的检验项目
1. 拟合程度判定(调整后的R2)
2. 回归方程的检验(F检验)【检验所有自变量与因变量之间的线性关系是否显著,是否可用线性模型来表示】
3. 回归系数的检验(t检验)【检验每个自变量对因变量的线性影响是否显著,对F检验的一个补充】
4. D.W检验(残差项是否自相关)
5. 共线性检验(多元线性回归)【自变量的容忍度(Tolerance)和方差膨胀因子(VIF)】
> 据经验 `T < 0.1` 一般认为具有多重共线性,当 `VIF >= 10` 时,就说明自变量 X 与其余自变量之间有严重的多重共线性【多重共线性的对策:增大样本量或减少自变量】
自变量筛选方法:`前进`、`后退`、`步进`
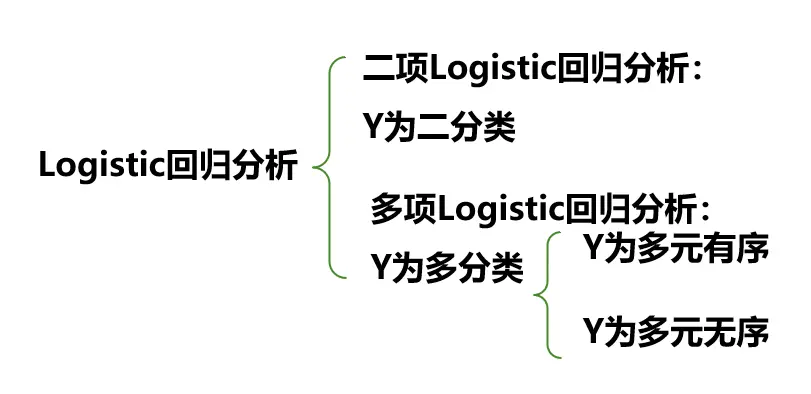
## logistic回归
线性回归的结果变量是连续的,逻辑回归是**离散的**
线性回归完成方式是建立线性的拟合线,逻辑回归方式是建立**决策线**【比如是否会购买某种商品,即因变量是**固定的**】
逻辑回归解决因变量不连续的问题。将离散变量转化为连续变量【因变量取值为1时的概率,概率的取值范围为0-1,连续变量】
二项逻辑回归方程的拟合优度检验:`Hosmer—Lemeshow检验`
Hosmer—Lemeshow检验的原假设:**观测频数的分布与期望频数分布无显著差异**。
Hosmer—Lemeshow统计量的值越小,p>a,拟合效果越好;反之,则拟合效果不好。【如果没有通过HL检验,需要考虑对变量进行降维或者增加样本量】
# 五、因子分析
**前言**【理解】:在实际问题的分析过程中,人们往往希望尽可能多的搜集关于分析对象的数据信息,进而能够比较全面的、完整的把握和认识它。于是,对研究对象的描述就会有很多指标。但是效果如何呢?如果搜集的变量过多,虽然能够比较全面精确的描述事物,但在实际建模时这些变量会给统计分析带来计算量大和信息重叠的问题。而消减变量个数必然会导致信息丢失和信息不完整等问题的产生。
> `因子分析`是解决上述问题的一种非常有效的方法。它以最少的信息丢失,将原始众多变量综合成较少的几个综合指标(因子),能够起到**有效降维**的目的。
>
> 因子分析是一种**降维**和**评价**(排序)的方法。
所以顺理成章地因子分析应具有以下特点:
* 因子分析要求样本的个数要足够多【样本个数至少是变量数的5倍以上】
* 因子个数远远少于原有变量的个数
* 因子能够反应原有变量的绝大部分信息
* 用于因子分析的变量必须是相关的
* 因子具有命名解释性
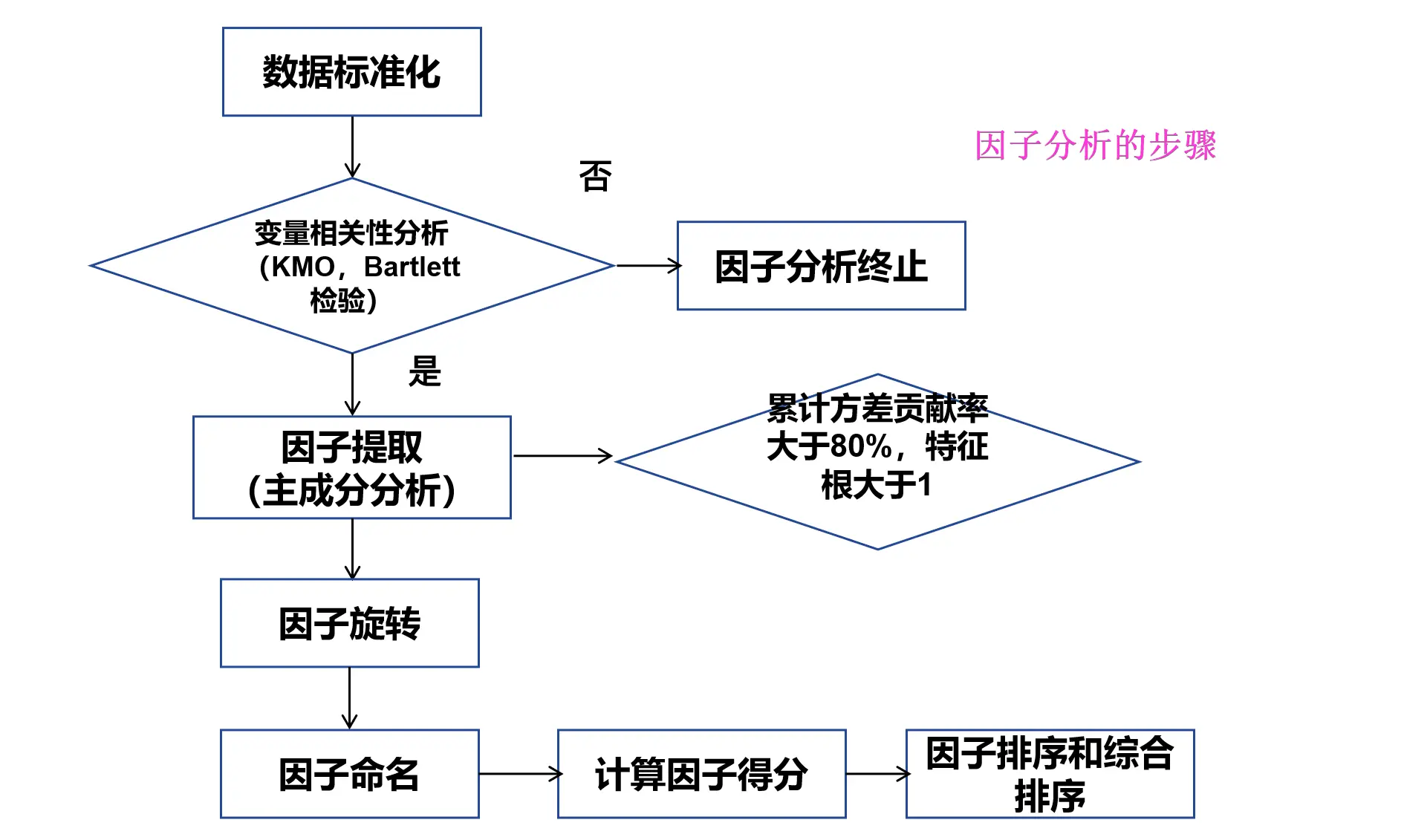
因子分析的结果分析:
**一般而言,KMO值大于0.5,巴特利球体检验sig小于0.05,表明可以进行因子分析。**
# 六、聚类分析
> 聚类分析是统计学中研究“物以类聚”的一种方法,属多元统计分析方法,所以,聚类分析前要检查各变量的量纲是否一致,不一致则需进行转换,如将各变量均作标准化转换就可保证量纲一致
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准, 聚类分析能够从样本数据出发,自动进行分类。聚类分析所使用方法的不同,常常会得到不同的结论。不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。 因此我们说聚类分析是一种探索性的分析方法。
**聚类分析有两种**:`K-Mean聚类分析`【快速聚类样本】,`层次聚类分析`【它有两种类型,一是对**研究对象的本身**进行分类,称为Q型聚类;另一是对**研究对象的观察指标**进行分类,称为R型聚类。同时根据聚类过程不同,又分为分解法和凝聚法。】
`两步聚类算法`是在SPSS中使用的一种聚类算法,是BIRCH层次聚类算法的改进版本【两个阶段:预聚类阶段,聚类阶段】
# 七、比较分析:t检验
| 特征 | 独立t检验 | 配对t检验 |
| ---- | ----------------------------- | ---------------------------------------------------------- |
| 用途 | 比较两组独立样本的平均值是否有显著差异 | 比较两组相关联样本的平均值是否有显著差异 |
| 样本类型 | 两组被比较的样本是独立的 | 两组被比较的样本是相关联的 |
| 示例场景 | 比如两个不同班级的学生在某个考试中的平均分是否存在显著差异 | 比如同一组学生在两个不同时间点的考试成绩是否存在显著差异,或者同一组被试接受了两种不同的治疗方式,效果是否有显著差异 |
**主要还是看t检验对应的sig值,如果大于0.05,则说明没有显著差异,小于0.05,则具有显著差异**
# 八、分析思路(全)【重点,主要理解】
> 设计信息分析的设计思路、数据源、分析方法、分析过程【不用详细】、应用
这部分开始之前,需要先了解信息分析的工作目标:【认识、了解】
* 从混沌的信息中萃取出有用的信息
* 从表面信息中发现相关的隐蔽信息
* 从过去和现在的信息中推演出未来的信息
* 从部分信息中推知总体的信息
* 运用相关信息对事物的状态、效能、效果进行评价
## 8.1设计思路
这里我能想到的就是
1. 明确分析目的和目标:确定信息分析要回答的问题或实现的目标,以便收集和分析相关数据来支持决策。
2. 确定分析对象和范围:确定信息分析的对象和范围,以便收集和分析相关数据来支持决策。
## 8.2数据源
[数据源🔽](#data)
## 8.3分析方法【建立分析模型】
信息分析是`定性分析`和`定量分析`相结合的分析。纯定性分析一般不明确地认定分析模式,而定量分析的分析结果是否有效,很大程度上取决于数据与能够处理这种数据的模型之间的配合。
在计算机技术十分发达的今天,通过搜集到的数据和已有模型的运算,得出信息分析所需的结论,并不是一件十分难的事情。而找到一个合适的分析模型,并将数据很好地代入其中,则是分析技术中的难点。
1. `定量分析方法`:使用数字和统计方法来分析数据,如回归分析、方差分析、时间序列分析等。
2. `定性分析方法`:使用非数字的方法来分析数据,如文本分析、内容分析、案例分析等。
> 例如专利分析中:**定量分析**词频、申请量、分类号、国别、申请人等,**定性分析**专利内容、质量等
然后按照上面的设计思路来进行回归分析,比较分析等建立分析模型
## 8.4分析过程
1. 数据收集:从数据源收集相关的数据。
2. 数据清洗:对收集到的数据进行清洗,包括去除重复数据、错误数据和无效数据。
3. 数据分析:使用分析方法对数据进行分析,以提取有价值的信息。【搭配描述 `拟合优度`/`显著性` 检验确立下一步分析方法】
4. 构建预测模型:使用分析结果构建预测模型,以对未来的事件或趋势进行预测。【可选】
5. 模型评估:对预测模型进行评估,以确定模型的准确性和可靠性。
## 8.5应用
1. 销售预测:通过分析历史销售数据、市场数据、经济数据等,来预测未来的销售额。
2. 财务预测:通过分析财务数据、经济数据等,来预测公司的财务状况和盈利能力。
3. 市场预测:通过分析市场需求、市场竞争、市场趋势等,来预测市场的未来发展。
4. 技术预测:技术发展趋势分析 、技术分布分析 、核心专利分析
# 九、补充
补充的主要是对上述重点没有特别提要的,但是会考到的知识的补充
## 信息分析的一些概论
> 信息分析和数据分析、情报分析的区别
数据(Data) ————> 数据分析
信息(Information) ————> 信息分析 信息+分析=情报
情报(Intelligence) ↔ 情报分析(双向影响)
> 情报(Intelligence)是信息的一种特殊类型,它是“关于对手的信息”。
>
> `信息分析`是指以社会用户的特定需求为依托,以定性或定量的研究方法为手段,通过对文献信息的**收集、整理、鉴别、评价、分析、综合**等系列化加工过程,形成新的、增值的信息产品,最终为不同层次的科学决策服务的一项具有科研性质的智能活动。
> `商业分析`通过数据分析趋势、构建预测模型、优化企业流程,提升企业绩效,以促进商业目的的实现。
商业分析有以下三种类型:
1. 描述性分析:描述分析以前发生了什么?
2. 预测性分析:预测未来会发生什么?
3. 规范性分析:描述将产生最佳结果的最佳方法。
> 根据信息分析的功能来划分可以分为:
>
> `跟踪型`、`比较型`、`预测型`、`评价型`、`对策型`、`综合型`信息分析
>
> 信息分析活动又可以分为:**描述性分析**【使原有信息清晰】、**推断性分析**【发现新的知识】。
## 数据源的获取
> 信息是分析的原材料,在没有搜集到足够的信息之前,任何分析都无从开始。信息搜集需要了解信息源,掌握信息搜集方法。文献阅读、信息检索、网络搜寻、问卷调查、访谈、实地考查、购买情报、人际网络等,都是信息搜集的常用方法。【找到需要的信息】