
数据结构与算法考试相关-2024
考试题型 一. 选择题(10分,5题,每题2分) 二. 填空题(15分,5题,每题3分) 三. 简答题(15分,3题,每题5分,要求尽量详细,逻辑清晰,层次分明) 四. 代码题(关键处请写注释;如果需要用所学的数据结构,可以不用定义,直接import使用;请注意代码规范)(60分,6题,每题10分)
- 出题思路:从以下重点中出相应的题目,然后再随机选择上述题型和数目,再做微调。
考试重点
第1章 绪论
- 算法的定义 P8 算法是具有有限步骤的过程,依照这个过程便能解决问题。因此算法就是解决方案。
- 何谓编程 P13 编程是指通过编程语言将算法编码以使其能被计算机执行的过程。
-
编程语言的解释 P14-P15
编程语言必须提供一种标记方式:用于表达数据和过程,为此,编程语言提供了众多的数据类型和控制语句。

-
数据抽象的定义 P20
抽象数据类型(简称ADT)从逻辑上描述了如何看待数据及其对应运算而无须考虑具体实现,这意味着我们仅需要关心数据代表了什么。抽象数据类型的实现就是
数据结构
第2章 Python基础
- Python语言的基本情况 P5 Python是龟叔于20世纪90年代开发的高级计算机语言,截至2024/06/20,python最新的一个大版本是3.12
- Python解释器 P7 Python解释器可以接收并执行收到的python命令,然后返回结果。IDE
-
Python的注释 P12
-
Python的标识符和保留字 P17-P18
标识符通常被称为
变量,python中字母是大小写敏感的。不能以数字开头。
-
Python的赋值语句 P21-P24
赋值语句就是
=,例如: - Python中可变的类和不可变的类 P33-P51 这部分应该熟了,可以参考👉https://www.cnblogs.com/poloyy/p/15073168.html
-
Python的运算符 P54-P64
-
Python的输入和输出 P99-P105
-
迭代器和可迭代对象 P121
可迭代对象:https://docs.pythontab.com/interpy/Generators/Iterable/
迭代器:https://docs.pythontab.com/interpy/Generators/Iterator/
-
迭代器和生成器 P125
生成器:https://docs.pythontab.com/interpy/Generators/Generators/
-
一行写条件表达式 P129
-
语法解析 P132
-
打包和解包 P134-P135
如果在大的上下文中给出了一系列逗号分隔的表达式,它们将被视为一个单独的元组,即使没有提供封闭的圆括号。这个过程就是
自动打包。Python 允许单个标识符的一系列元素赋值给序列中的各个元素。右边的表达式可以是任何迭代类型,只要左边的变量数等于右边选代的元素数。这个过程就是自动解包。 - 作用域和命名空间 P137-P140 如果不太熟悉可以参考👉https://www.runoob.com/python3/python3-namespace-scope.html
第3章 面向对象编程
-
面向对象的设计目标 P6
面向对象设计目标有三个:
健壮性:能够处理未定义的异常输入适应性:可移植的可重用性:同样的代码可以用在不同系统的各种应用中
-
面向对象的设计原则 P11
- 模块化:把程序设计为一个个小方块,各方块相互独立
- 抽象化:就是抽象
- 封装:软件系统的不同组件不应显示其各自实现的内部细节。这点类似于黑盒子。
- 抽象数据类型 P14 ADT(Abstract Data Types)是数据结构的数学模型,它规定了数据存储的类型、支持的操作和操作参数的类型。
- 封装的概念 P17 同上述⬆️
- 软件开发的三个主要阶段 P25 设计->实现->测试和调试
- UML图的内容 P31 包含类名、实例变量、方法。
- 编程风格(不会有专门的题,但编程题要符合该风格) P35 这个真喷不了,可以参考🤣:https://itniuma.com/article/2023.06/1.html
-
如何做测试 P42
类似之前的黑盒测试,
方法覆盖和语句覆盖,python中可以参考:https://www.youtube.com/watch?v=5Md_3ZeuYPc - 如何做调试 P43 最简单的print()或者用IDE中提供的Debugger可以更好地进行跟栈。
-
运算符重载 P55,P58-P59
Python中允许同一运算符根据上下文具有不同的含义,例:
但是对于上述的加法,应用于python内置类还行,自己定义的类是不能直接这样相加的。但可以通过定义来实现类的运算:
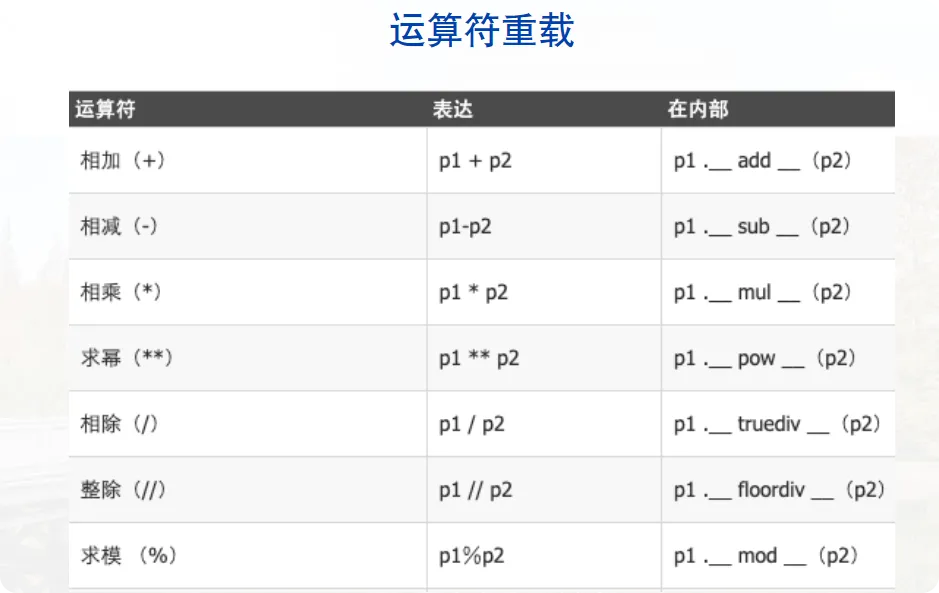
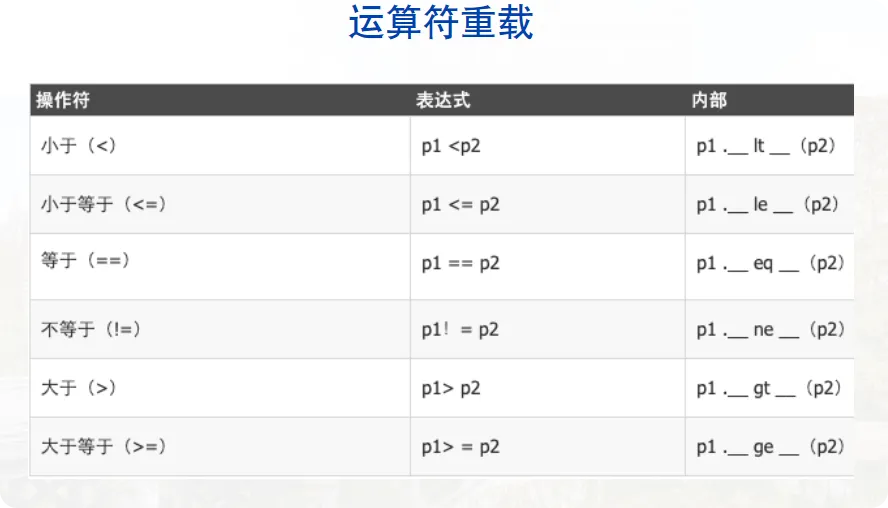
- 继承的概念 P67 在面向对象的编程中,模块化和层次化组织的机制称为继承。 继承允许基于一个现有的类作为起点定义新的类。父类(又称为超类或基类)、子类。 子类可以提供新的方法覆盖父类现有的方法,也可以提供全新的扩展方法
- 抽象基类的概念 P77 在经典的面向对象的术语中,如一个类的唯一目的是作为继承的基类,那么这个类就是一个抽象基类。例如鹦鹉和海鸥可以抽象出一个带有翅膀、会飞翔、有尖嘴…的一个动物,但没有具体的一个现实实例是这样的。
-
类、对象、子类的命名空间 P80
每个已定义的类都有一个单独的类命名空间。这个命名空间用于管理一个类的所有实例所共享的成员或没有引用任何特定实例的成员。

- 判断深拷贝和浅拷贝 P82-P84 参考👉:https://www.runoob.com/w3cnote/python-understanding-dict-copy-shallow-or-deep.html
第4章 算法分析
-
什么是数据结构和算法 P9
数据结构是组织和访问数据的一种系统化方式。算法是在有限的时间里一步步执行某些任务的过程。 - 算法分析的维度 P9 时间复杂度和空间复杂度
-
影响算法运行时间的因素 P12
除了算法本身,影响运行时间的其他因素:
- 输入数据的大小
- 硬件环境和软件环境
- 程序是编译执行还是解释执行
- 实验分析的挑战 P17 很难直接比较两个算法的实验运行时间、实验只有在有限的一组测试输入下才能完成。
- 如何分析算法效率 P19-P22 计算原子操作、随着输入函数的变化进行测量操作、最坏情况输入的研究
- 大O记法 P26-P27 O(n),相信你一定知道。
- 8种函数 P29-P45 常见时间复杂度从低到高排列有 𝑂(1)、𝑂(log𝑛)、𝑂(𝑛)、𝑂(𝑛log𝑛)、𝑂(𝑛2)、𝑂(2n) 和 𝑂(𝑛!) 等。
-
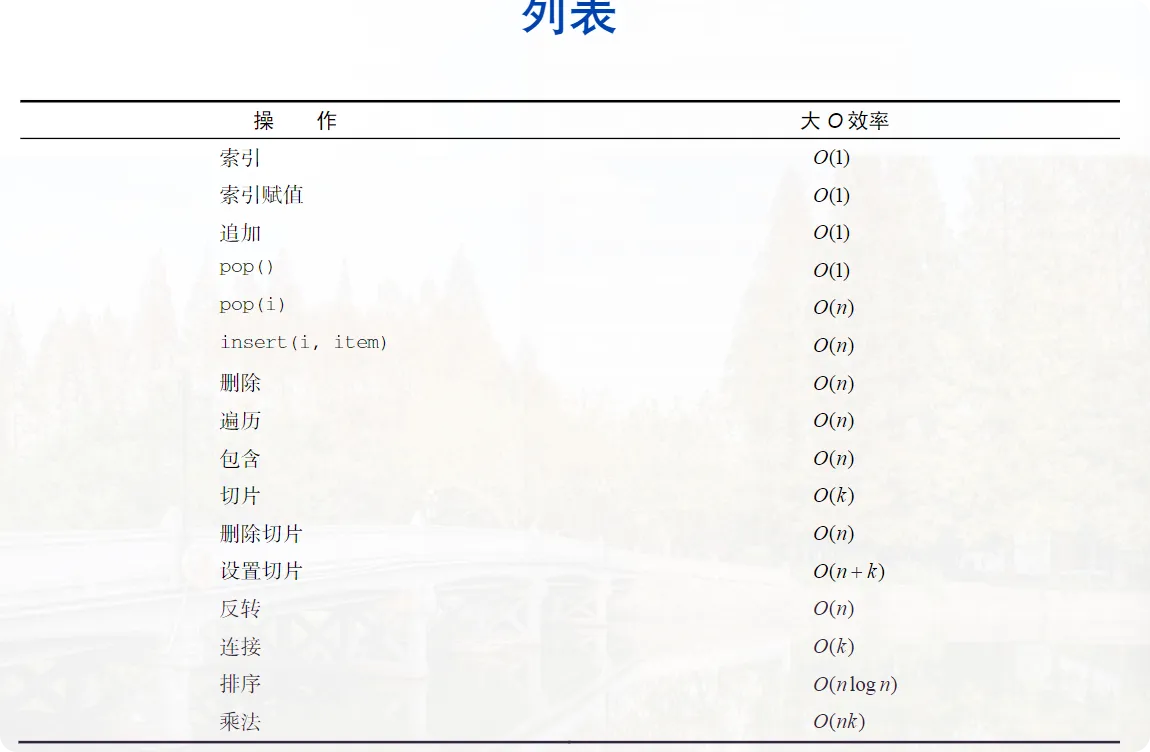
列表的性能(不用区分n和k) P47
-
字典的性能 P49

-
异序词检测问题的代码 P51-P58
问题:如果一个字符串只是重排了另一个字符串的字符,那么这个字符串就是另一
个的异序词,比如 heart 与 earth,以及 python 与 typhon。简化问题:两个字符串的长度相同,并且都由26个英文字母的小写组成。
第5章 递归
-
递归的定义和三原则 P4
递归定义:- 通过一个函数在执行过程中一次或多次调用其本身
- 或者通过一种数据结构在其中表示依赖于相同类型的结构更小的实例
- 递归算法必须有基本情况(即停止递归的条件——可直接解决的问题)
- 递归算法必须改变其状态并向基本情况靠近;
- 递归算法必须递归地调用自己
-
计算一列数之和的递归解法 P9
-
阶乘的递归解法 P14
-
将整数转换成任意进制字符串的递归解法 P20
-
二分查找 P25
-
汉诺塔问题 P37-P42
第6章 基本数据结构
-
Python中的序列类型 P6
list,tuple,string -
计算机中内存的存储和检索 P8
计算机主存由
位信息组成,这些位通常被归类成更大的单元,这些单元则取决于精准的系统架构。一个典型的单元就是一个字节,相当于8位。存储器(RAM)的任一单个字节被存储或检索的运行时间为O(1)。每个字节都被指定了连续的存储地址。 -
理解列表和元组存放的是引用 P14-18
这段内容可以和深拷贝、浅拷贝一块理解。
-
动态数组的实现 P27
-
二维数组的构建 P43-P46
- 栈的定义 P50 栈(stack)是一种遵循先入后出逻辑的线性数据结构。
-
栈的抽象数据类型 P55-P56
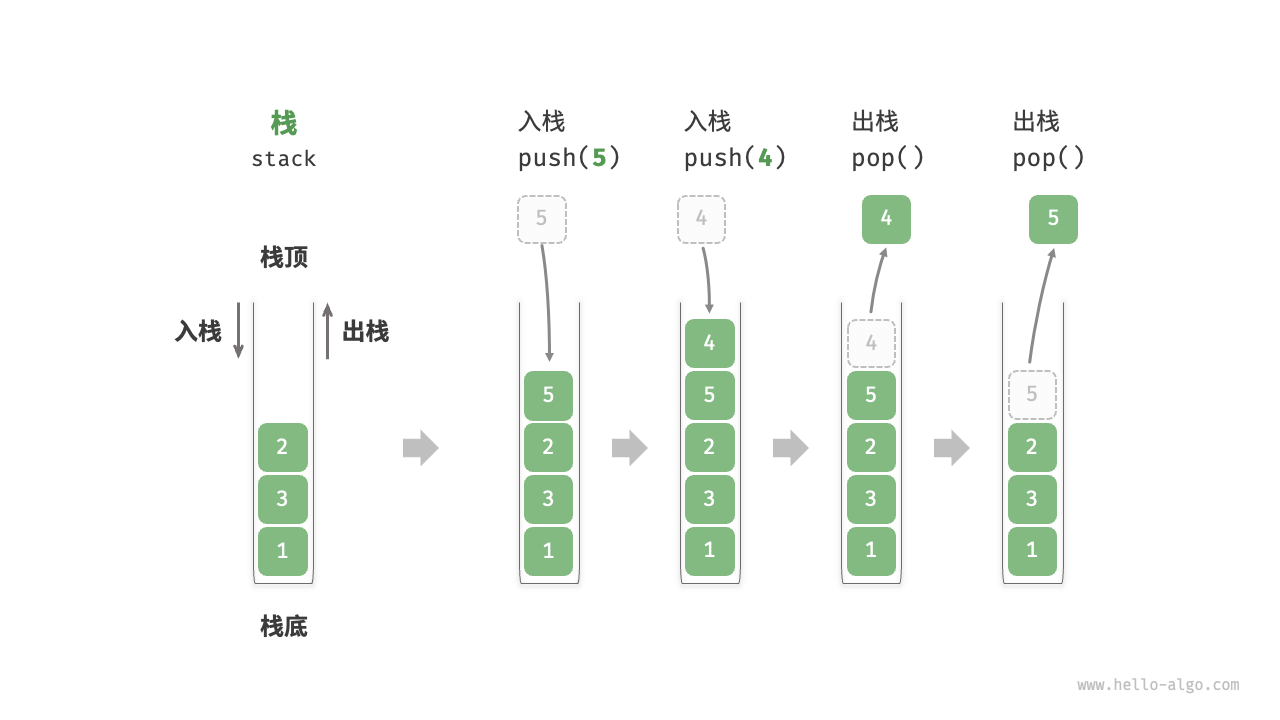
方法 描述 时间复杂度 push() 元素入栈(添加至栈顶) O(1) pop() 栈顶元素出栈 O(1) peek() 访问栈顶元素 O(1) -
栈的实现 P61
-
括号匹配的代码实现 P69
-
标记语言的标签匹配的代码实现 P72
-
十进制转换成任意进制数的代码实现 P75
-
实现python的运算:先从中序转后序,再计算后序 P87,P93
- 队列的定义 P95,P97 队列(queue)是一种遵循先入先出规则的线性数据结构。顾名思义,队列模拟了排队现象,即新来的人不断加入队列尾部,而位于队列头部的人逐个离开。
-
队列的抽象数据类型 P98
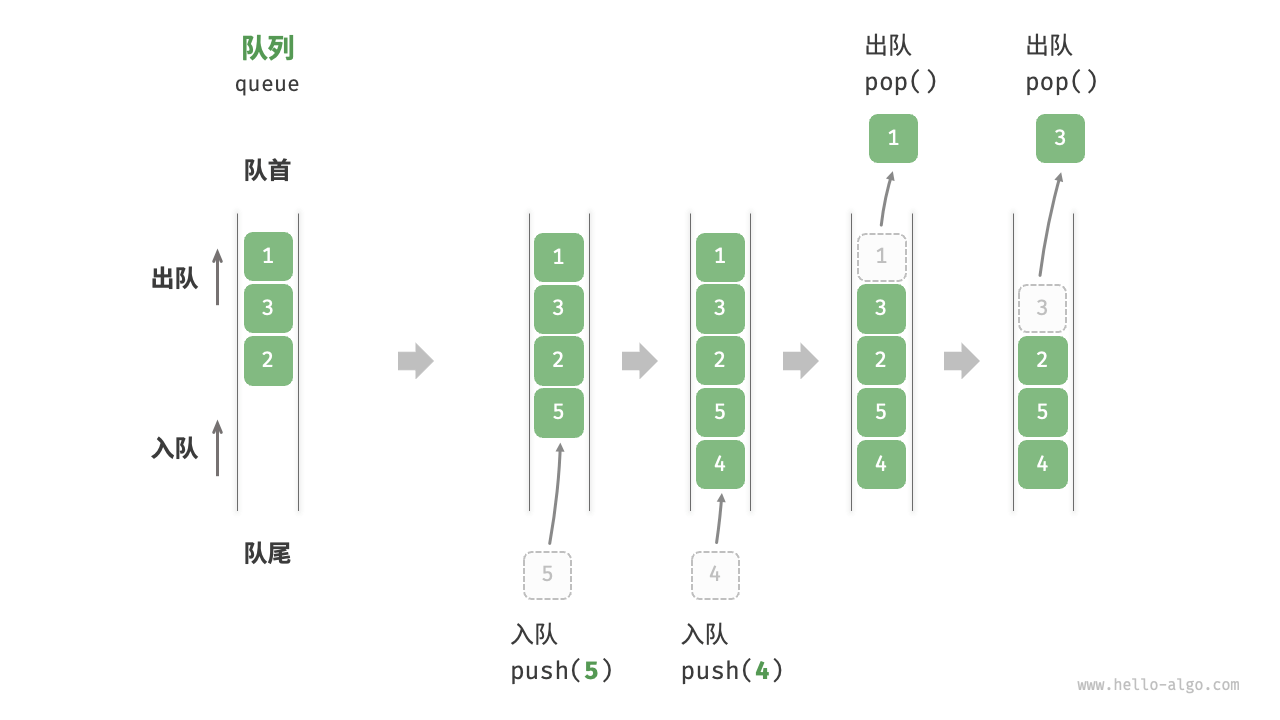
方法 描述 时间复杂度 push() 元素入队,即将元素添加至队尾 O(1) pop() 队首元素出队 O(1) peek() 访问队首元素 O(1) -
队列的实现 P101
-
传土豆的代码实现 P105
- 双端队列的定义 P107 在队列中,我们仅能删除头部元素或在尾部添加元素。双向队列(double-ended queue)提供了更高的灵活性,允许在头部和尾部执行元素的添加或删除操作。
-
双端队列的抽象数据类型 P108
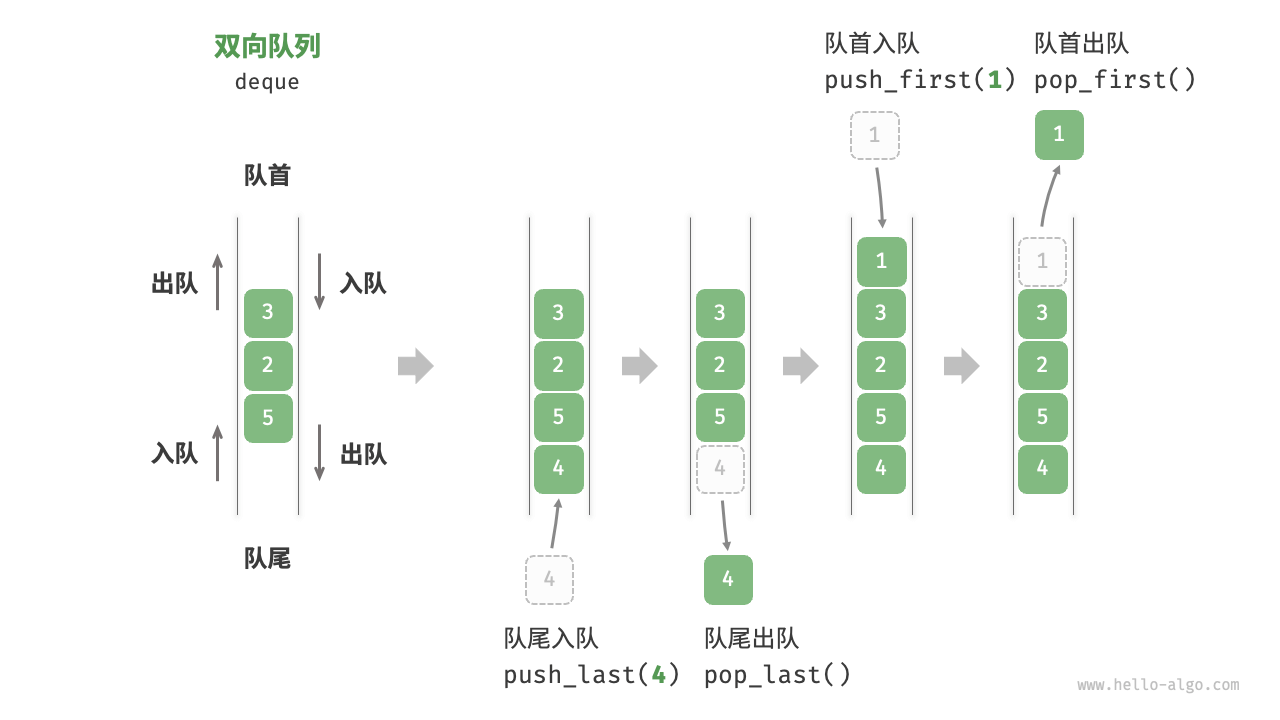
方法名 描述 时间复杂度 push_first()将元素添加至队首 O(1) push_last()将元素添加至队尾 O(1) pop_first()删除队首元素 O(1) pop_last()删除队尾元素 O(1) peek_first()访问队首元素 O(1) peek_last()访问队尾元素 O(1) -
双端队列的实现 P110
-
回文检测器的实现 P113
-
列表的缺点 P115
- 一个动态数组的长度可能超过实际存储数组元素所需的长度
- 在实时系统中对操作的摊销边界是不可接受的
- 在一个数组内部执行插入和删除操作的代价太高
- 链表的定义 P116-P118 链表(linked list)是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。引用记录了下一个节点的内存地址,通过它可以从当前节点访问到下一个节点。
-
链表的抽象数据类型 P119-120
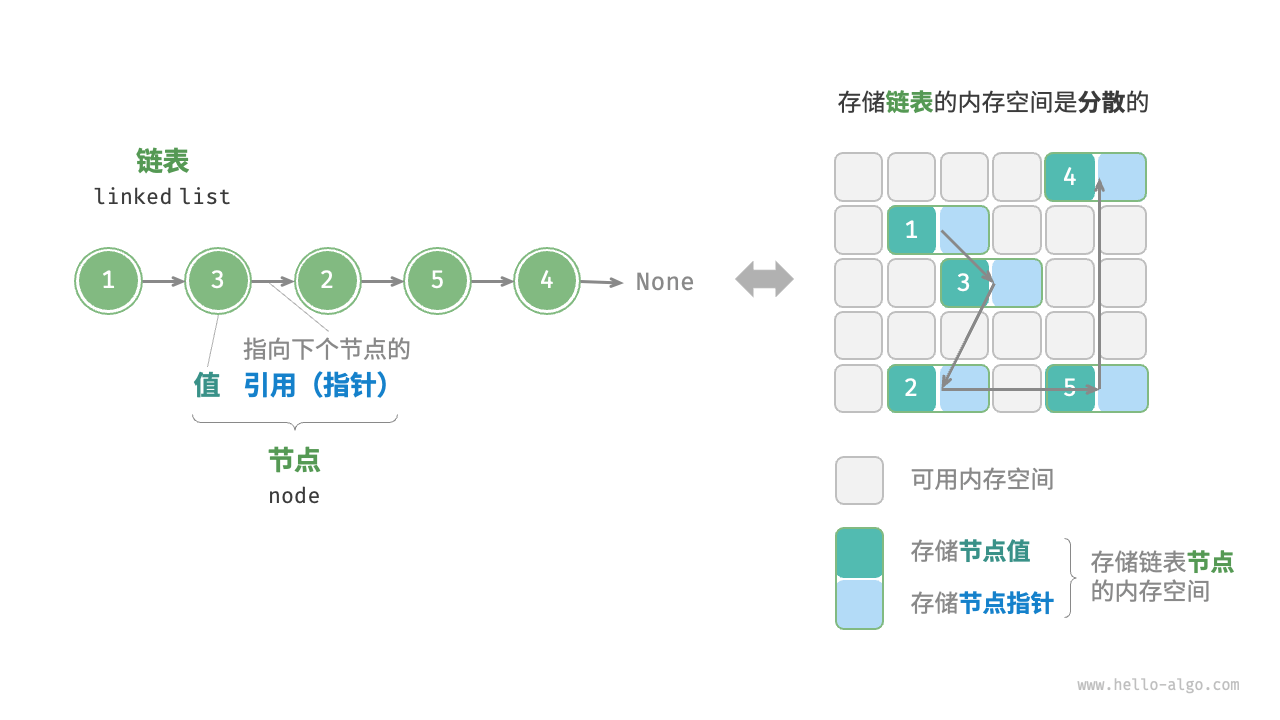
数组(List) 链表 存储方式 连续内存空间 分散内存空间 容量扩展 长度不可变 可灵活扩展 内存效率 元素占用内存少,但可能浪费空间 元素占用内存多 访问元素 O(1) O(n) 添加元素 O(n) O(1) 删除元素 O(n) O(1) -
链表的实现 P121-P139
-
具备解决新问题的能力(对已有问题的简单扩展)

第7章 搜索和排序
搜索是一场未知的冒险,我们或许需要走遍神秘空间的每个角落,又或许可以快速锁定目标。-
无序的顺序搜索的实现和分析 P9-P10
-
有序的顺序搜索的实现和分析 P12-P13
-
三种二分搜索的实现和分析 P16-P21
对于上述的两种递归,第二种更好因为第二种是对原始
data进行索引,没有创建新的列表。时间复杂度都是O(logn) -
散列表的定义和目标 P24-P32
哈希表(hash table),又称散列表,它通过建立键
key与值value之间的映射,实现高效的元素查询。具体而言,我们向哈希表中输入一个键key,则可以在 𝑂(1) 时间内获取对应的值value。这样就解决了列表搜索只能循环查找的问题。 哈希冲突:从本质上看,哈希函数的作用是将所有key构成的输入空间映射到数组所有索引构成的输出空间,而输入空间往往远大于输出空间。因此,理论上一定存在“多个输入对应相同输出”的情况。例如: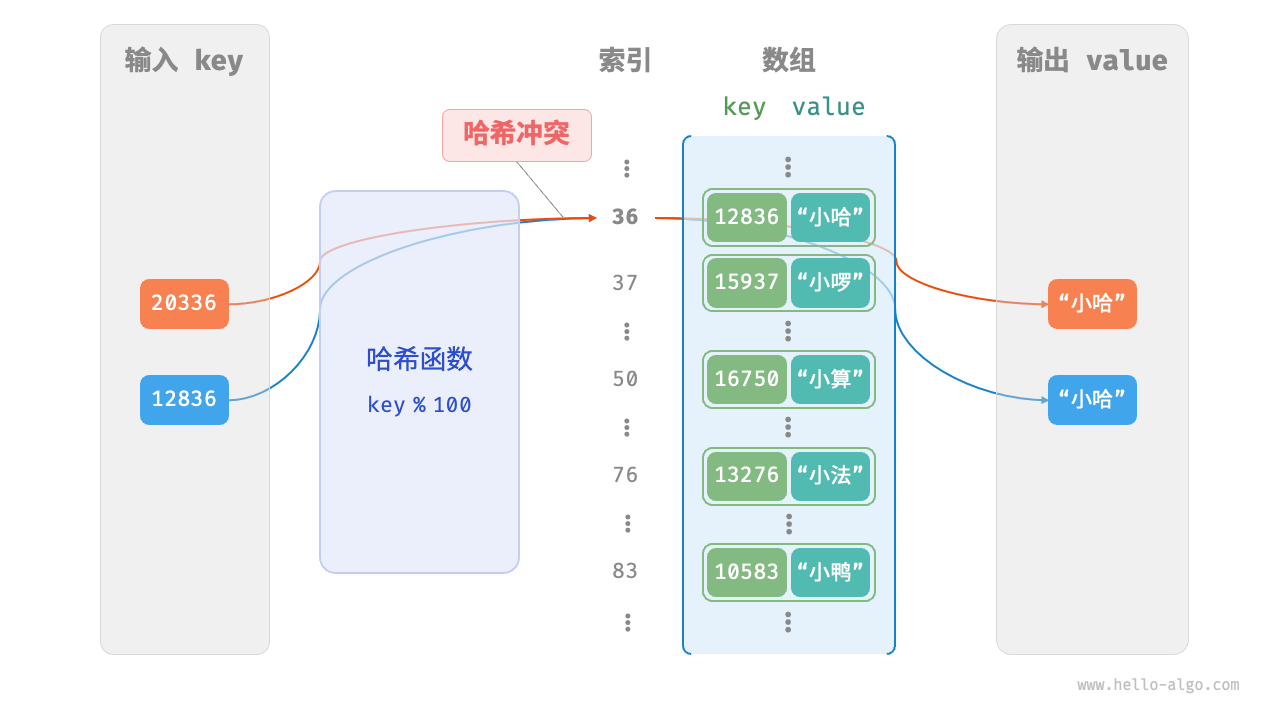 可以通过扩容哈希表容量来减少冲突。
可以通过扩容哈希表容量来减少冲突。
-
常用的散列函数 P32-P37
-
再散列的方法 P39-P49
再散列泛指在发生冲突后寻找另一个槽的过程。这里引入一个解决哈希冲突的一个方法:开放定址法可参考👉https://www.cnblogs.com/east7/p/12594894.html 还有一种方法是链接法就是允许哈希表同一个位置存在多个元素,也就是位置上存储的是元素集合。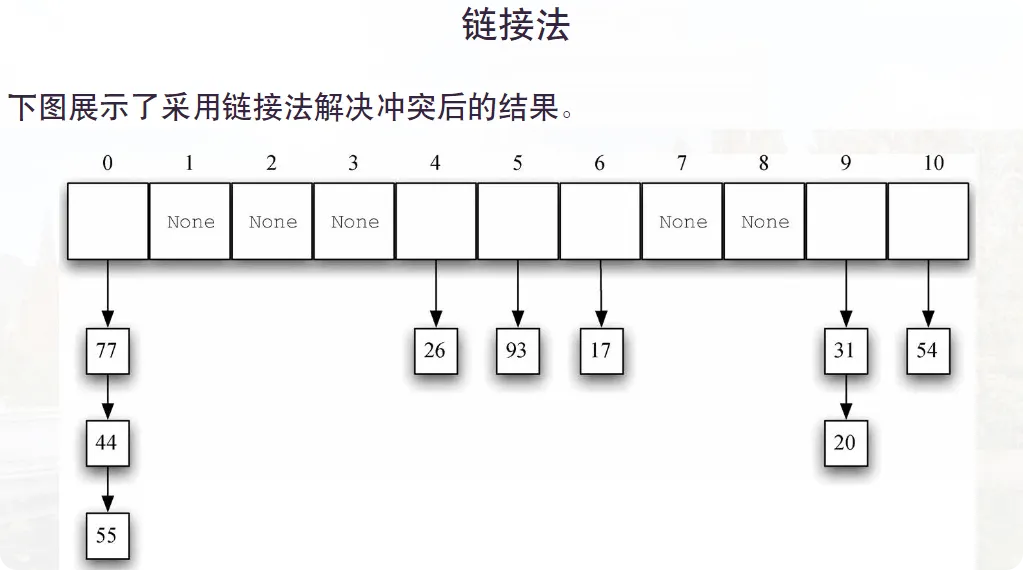 但是这种方法也是有缺陷的:
但是这种方法也是有缺陷的:
- 由于每个槽都有一个元素集合,因此需要再搜索一次,才能得知目标元素是否存在
-
HashTable P55-P56
-
分析散列搜索算法 P58
引入一个定义:
载荷因子,表示哈希表的占用率,已被占用槽数/总槽数
- 排序过程 P61 首先,排序算法要能比较大小;其次,当元素的排列顺序不正确时,需要交换它们的位置。
-
冒泡排序的实现和分析 P65-P66
冒泡排序(bubble sort)通过连续地比较与交换相邻元素实现排序。这个过程就像气泡从底部升到顶部一样,因此得名冒泡排序。- 首先,对 𝑛 个元素执行“冒泡”,将数组的最大元素交换至正确位置。
- 接下来,对剩余 𝑛−1 个元素执行“冒泡”,将第二大元素交换至正确位置。
- 以此类推,经过 𝑛−1 轮“冒泡”后,前 𝑛−1 大的元素都被交换至正确位置。
-
仅剩的一个元素必定是最小元素,无须排序,因此数组排序完成。
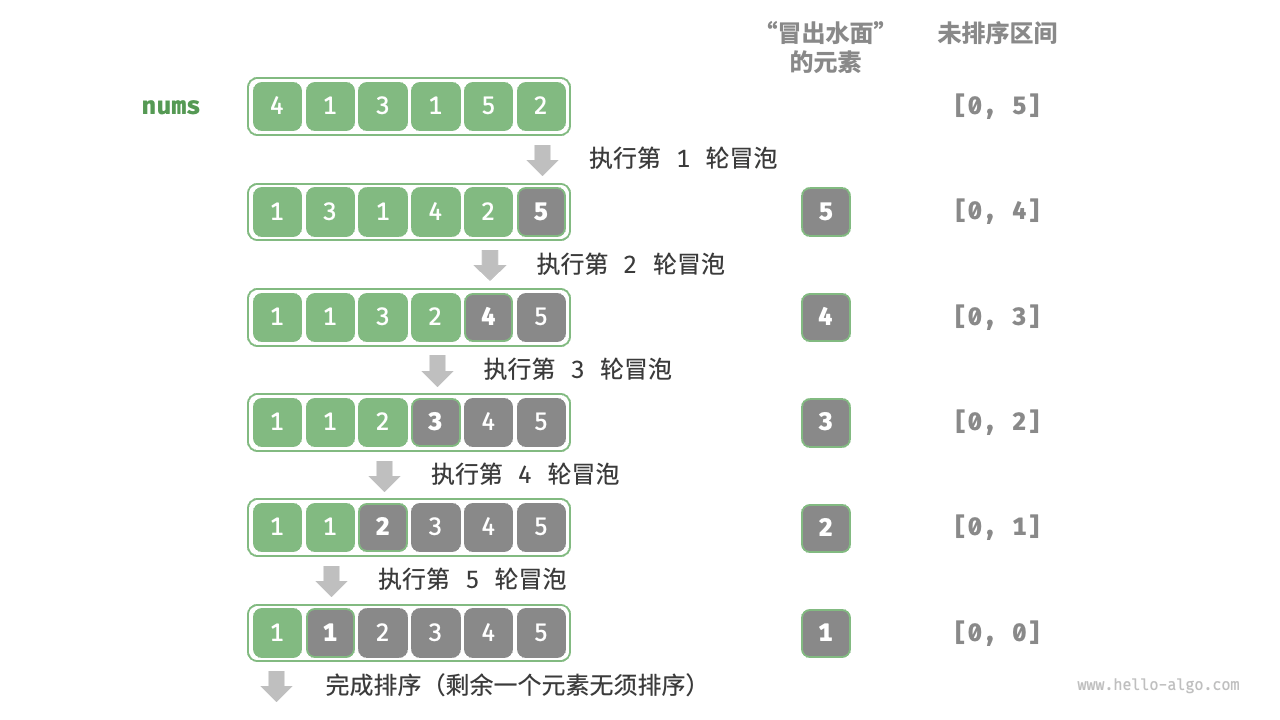
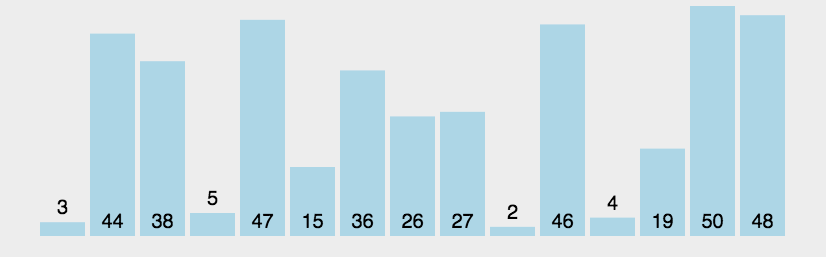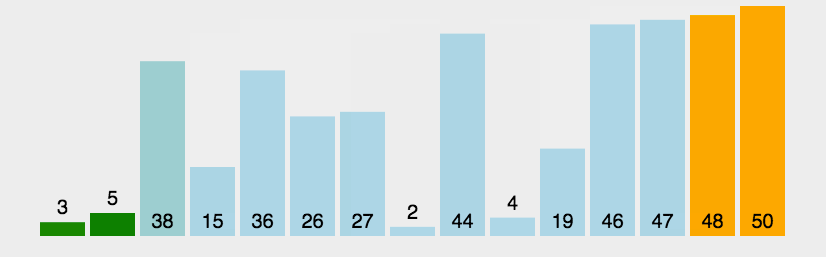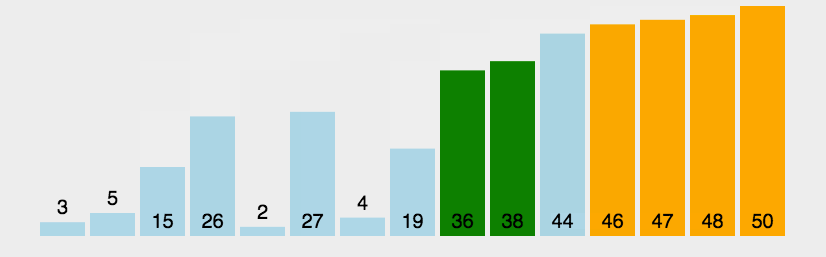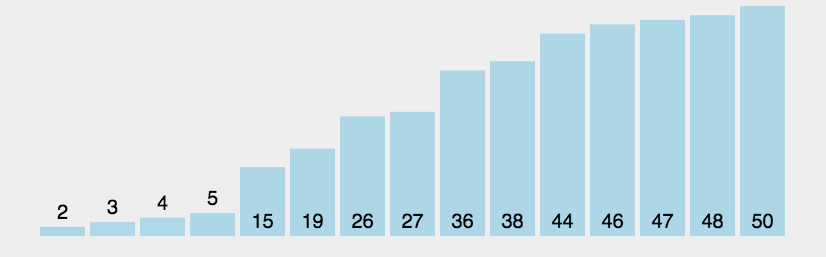
-
选择排序的实现和分析 P69-P70
选择排序(selection sort)的工作原理非常简单:开启一个循环,每轮从未排序区间选择最小的元素,将其放到已排序区间的末尾。- 设数组的长度为n,初始状态下,所有元素未排序,即未排序(索引)区间为 [0,𝑛−1] 。
- 选取区间 [0,𝑛−1] 中的最小元素,将其与索引 0 处的元素交换。完成后,数组前 1 个元素已排序。
- 选取区间 [1,𝑛−1] 中的最小元素,将其与索引 1 处的元素交换。完成后,数组前 2 个元素已排序。
- 以此类推。经过 𝑛−1 轮选择与交换后,数组前 𝑛−1 个元素已排序。
-
仅剩的一个元素必定是最大元素,无须排序,因此数组排序完成。
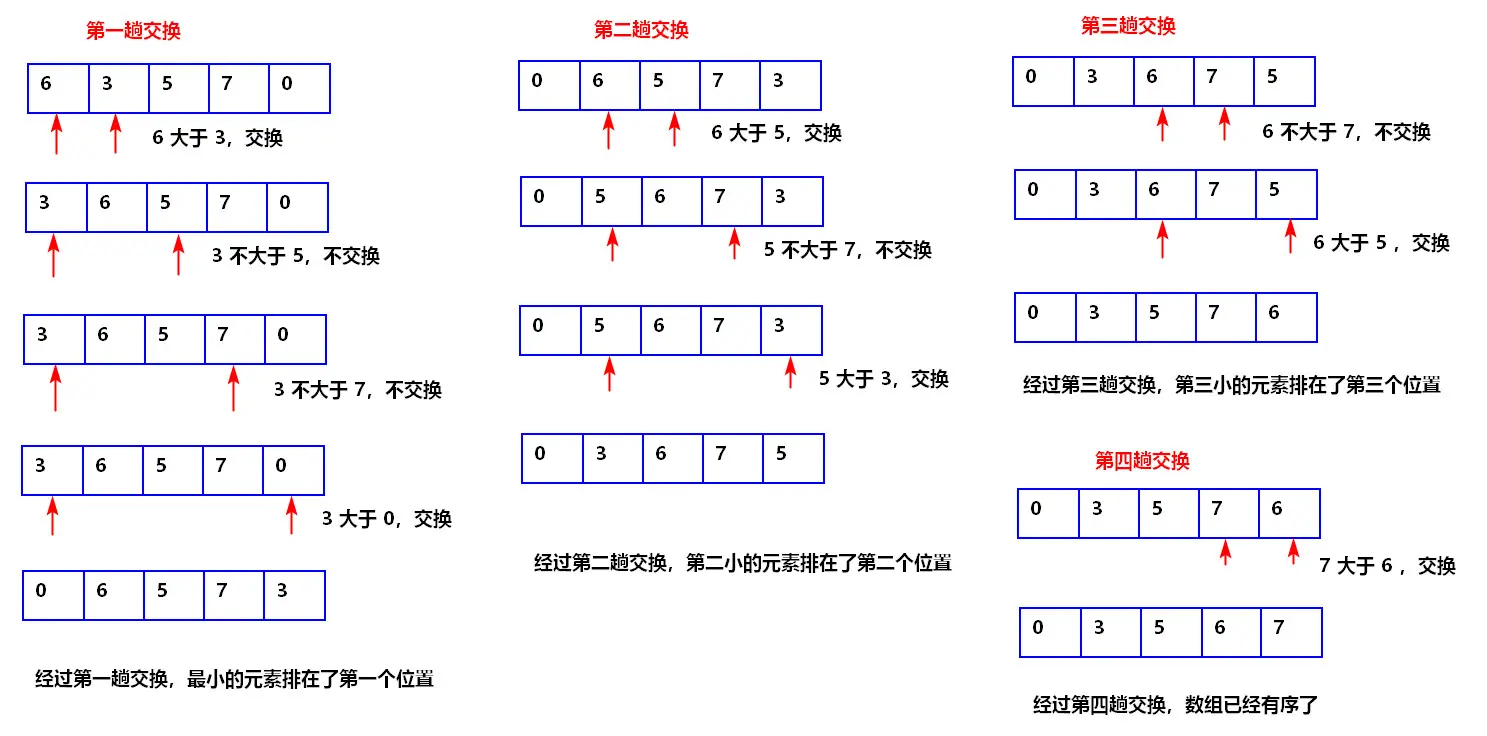
 说明:此动图为优化后的选择排序,每趟只交换一次
说明:此动图为优化后的选择排序,每趟只交换一次
-
插入排序的实现和分析 P73-P74
插入排序(insertion sort)是一种简单的排序算法,它的工作原理与手动整理一副牌的过程非常相似。 具体来说,我们在未排序区间选择一个基准元素,将该元素与其左侧已排序区间的元素逐一比较大小,并将该元素插入到正确的位置。- 初始状态下,数组的第 1 个元素已完成排序。
-
选取数组的第 2 个元素作为
base,将其插入到正确位置后,数组的前 2 个元素已排序。 -
选取第 3 个元素作为
base,将其插入到正确位置后,数组的前 3 个元素已排序。 -
以此类推,在最后一轮中,选取最后一个元素作为
base,将其插入到正确位置后,所有元素均已排序。
-
搜索和排序时间复杂度的总结 P91

8.总结
没有总结